


性能浮點處理一直與高性能CPU相關聯。在過去幾年中,GPU也成為功能強大的浮點處理平臺,超越了圖形,稱為GP-GPU(通用圖形處理單元)。新創新是在苛刻的應用中實現基于FPGA的浮點處理。本文的重點是FPGA及其浮點性能和設計流程,以及OpenCL的使用,這是高性能浮點計算前沿的編程語言。
各種處理平臺的GFLOP指標在不斷提高,現在,TFLOP/s這一術語已經使用的非常廣泛了。但是,在某些平臺上,峰值GFLOP/s,即,TFLOP/s表示的器件性能信息有限。它只表示了每秒能夠完成的理論浮點加法或者乘法總數。分析表明,FPGA單精度浮點處理能夠超過1 TFLOP/s。
一種不太復雜的常用算法是FFT。使用單精度浮點實現了4096點FFT。它能夠在每個時鐘周期輸入輸出四個復數采樣。每一個FFT內核運行速度超過80 GFLOP/s,大容量FPGA的資源支持實現7個這類的內核。
但是,如圖1所示,這一FPGA的FFT算法GFLOP/s接近400 GFLOP/s。這是“按鍵式”OpenCL編譯結果,不需要FPGA專業知識。使用邏輯鎖定和DSE進行優化,7內核設計接近單內核設計的Fmax,將其GFLOP/s提升至500,超過了10 GFLOP/s每瓦。
這一每瓦GFLOP/s要比CPU或者GPU功效高很多。對比一下GPU,GPU在這些FFT長度上效率并不高,因此,沒有進行基準測試。當FFT長度達到幾十萬個點時,GPU效率才比較高,能夠為CPU提供有效的加速功能。
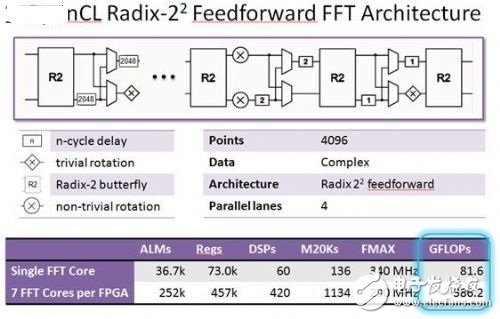
圖1:Altera Stratix V 5SGSD8 FPGA浮點FFT性能。
總之,實際的GFLOP/s一般只達到峰值或者理論GFLOP/s的一小部分。出于這一原因,更好的方法是采用算法來對比性能,這種算法能夠合理的表示典型應用的特性。算法越復雜,典型實際應用的基準測試就越具有代表性。 大功率電感廠家 |大電流電感工廠
